OCR
Author: Elia Giacobazzi | Ultimo aggiornamento: Venerdì 03 Marzo 2023 15:23
É possibile digitalizzare un documento storico completamente in automatico usando il Machine Learning?
É quello che ci siamo chiesti nel 2020, mentre cercavamo di trovare sinergie tra tecnologie informatiche open source e un progetto di preservazione della memoria storica del villaggio artigiano di Modena Ovest: AFOr.
Questa domanda ci ha portato a esplorare il mondo dei software OCR, il progetto open source tesseract e le sfide che la natura dei documenti storici genera in questo tipo di tecnologie.
Se siete interessati a come il machine learning, in generale, possa essere usato per fonti storiche vi rimando a quest’altro articolo: Machine Learning e Fonti Storiche
Le fonti storiche
Durante le attività del progetto AFOr sono state raccolti vari tipi di fonti storiche:
- interviste audio e video,
- oggettistica e strumenti di lavoro,
- foto d’epoca,
- volantini, giornali autoprodotti, libri
Quest’ultima categoria, unita alla volontà di voler sfruttare le competenze interne in Linguistica Computazionale, ci hanno diretti verso tecniche di trascrizione automatica … i software OCR.
OCR
Un OCR (Optical character recognition) è un processo (solitamente un software per computer) che permette di rilevare i caratteri contenuti in un documento (solitamente un’immagine) e convertirli in testo digitale (pagina di wikipedia per maggiori dettagli).
Nella pratica partendo da un immagine come una scansione o una foto contenente testo possiamo estrarre non solo i caratteri e le parole ma anche la loro posizione e struttura e salvarli in un formato facilmente sfruttabile in un sistema informatico.
I vantaggi di un processo di questo tipo sono:
- trascrizione automatica senza necessità di lavoro umano
- possibilità di ricercare particolari parole all’interno di grandi quantità di testo
- possibilità di ricercare pattern e relazioni mediante tecniche statistiche o di linguistica computazionale
- possibilità di riproporre il documento arricchito di funzionalità per aumentarne l’accessibilità
La demo
Nel nostro caso specifico, per rimanere il più possibile open source, abbiamo usato la libreria tesseract, e in particolare la sua implementazione python pytesseract.
Abbiamo realizzato una demo che permette di caricare un immagine, selezionare delle regioni di testo ed estrapolare il contenuto.
Per i curiosi ecco il link alla demo su github e il video di presentazione:
Problemi e risultati
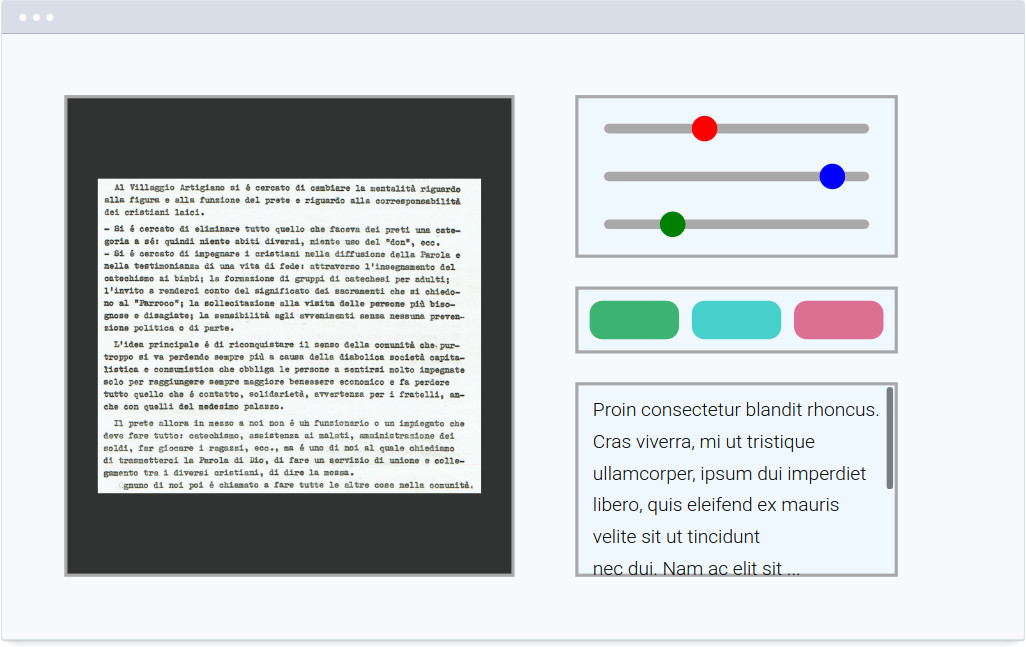
Nel corso dei test che abbiamo condotto ci siamo scontrati con varie problematiche principalmente legate alla difficoltà, ben nota in letteratura, dei software OCR nel gestire caratteri scritti a mano o con elevata imprecisione.
Nel caso del Giornale della Casona, il problema sorge dalle caratteristiche delle macchine ciclostile usate all’epoca e dalla non eccelsa qualità delle scansioni (eseguite molto prima di valutare l’uso di OCR).
Siamo però riusciti a estrarre del testo sufficientemente buono da fare varie analisi linguistiche, la trascrizione automatica non è eccelsa, ma velocizzerebbe di molto il processo di trascrizione manuale e la libreria tesseract, essendo open, ci permette di trovare nuove strategie per migliorare i risultati.
Obiettivi futuri
Il progetto OCR è ancora lontano dalla sua conclusione, stiamo esplorando varie possibilità per potenziare tesseract sulle foto in nostro possesso (tramite una procedura chiamata fine tuning) in modo da avere trascrizioni migliori.
Stiamo inoltre valutando di renderlo più adattabile ai vari supporti informatici che utilizziamo tramite un API web.
Laboratorio realizzato per il Festival Filosofia